AWS Cloudwatch Log auto export to S3 (자동 추출)
1. 사용하는 이유 및 아키텍처
AWS CloudWatch를 이용해서 로그들을 수집하고, 분석할 수 있다.
이때 CloudWatch에 로그들의 보존 기간을 정할 수 있는데, CloudWatch에 로그들을 영구적으로 저장하는 것이 저렴할까? S3에 저장하는 것이 저렴할까에 대한 생각을 하게 됐고, 비용을 비교해 보고, S3에 저장하는 것이 더 저렴하다면, 자동으로 Export 하는 아키텍처를 설계를 목표로 했다. 먼저 비용을 비교해 보자.
CloudWatch 비용

GB당 0.0314 USD의 가격이 나온다. 이제 S3와 비교해 보자.
S3 Standard 유형의 경우에는 저장하는 데이터 양에 따라 다르지만 일반적으로 20%가량 저렴하다. 하지만 아카이브 개념의 저장만 하는 데이터의 경우 LifeCycle을 이용하여 S3 Glacier에 적용한다면, 40%가 넘게 저렴하게 이용할 수 있다. S3 Glacier에 대한 비용은 여기서 살펴보지 않겠다.
따라서 20~40%가량의 데이터를 저장하는 비용을 아낄 수 있다. 그렇다면 어떻게 구현할지에 대해서 알아보자.
CloudWatch의 로그들을 자동으로 일정 시간마다 S3로 Export 해야 하기에 CronJob을 기반으로 설계를 진행할 예정이다.
이제 내가 설계한 아키텍처를 살펴보겠다.
1. EventBridge
애플리케이션 혹은 쿠버네티스를 사용한다면, CronJob을 직접 사용해도 되지만, 별도의 작업 없이 이벤트만 발생시키므로 가격이 저렴한 EventBridge를 선택했다. 비용은 아래와 같고 매월 1400만건이 무료이므로, 로그의 이벤트만 발생시키는 일반적인 상황에선 과금이 발생할 일이 거의 없다.
2. SNS
주제와 구독자를 생성하여, 어떠한 이벤트가 발생했을 때 구독자가 실행될 수 있게끔 할 수 있다. Lambda를 바로 구독자로 설정할 수 있지만, 나는 SQS를 구독자로 설정했다.
그 이유는 Lambda의 최대 실행 시간은 15분이다. 많은 로그들을 Export 한다면, 실행 시간이 초과할 수 있다. CronJob의 시간을 짧게 설정하는 방법이 있지만, 그것보단 복원력 있는 아키텍처 설계를 위해 SQS로 했다. 동작은 EventBridge에서 CronJob이 발생하면, SNS에 토픽이 게시되고, 구독자가 실행될 수 있게 해 준다.
SNS 비용은 아래와 같고 SQS를 구독자로 사용하므로, 비용은 SQS에 의존된다.
3. SQS
AWS의 메시지 큐 시스템으로 메시지가 들어온다면, 해당 메시지를 트리거로 가지고 있는 서비스 혹은 애플리케이션에 넘길 수 있다. SNS와 같이 사용한다면, 여러 개의 SQS를 둘 수 있고, 이를 각각의 Lambda가 트리거하면, Lambda의 최대 실행 시간에 대한 제한을 많이 해소할 수 있다.
그 이유는 로그 그룹들마다 SQS를 생성하고, 이에 알맞은 Lambda를 생성하면 되기 때문이다. 또한 실패했을 때 SQS의 DeadLetter서비스를 이용한다면, 어떤 것들이 실패했는지 알 수 있고, 재실행을 할 수 있는 기반이 된다.
SQS의 비용은 아래와 같고 매우 저렴한 것을 알 수 있다.
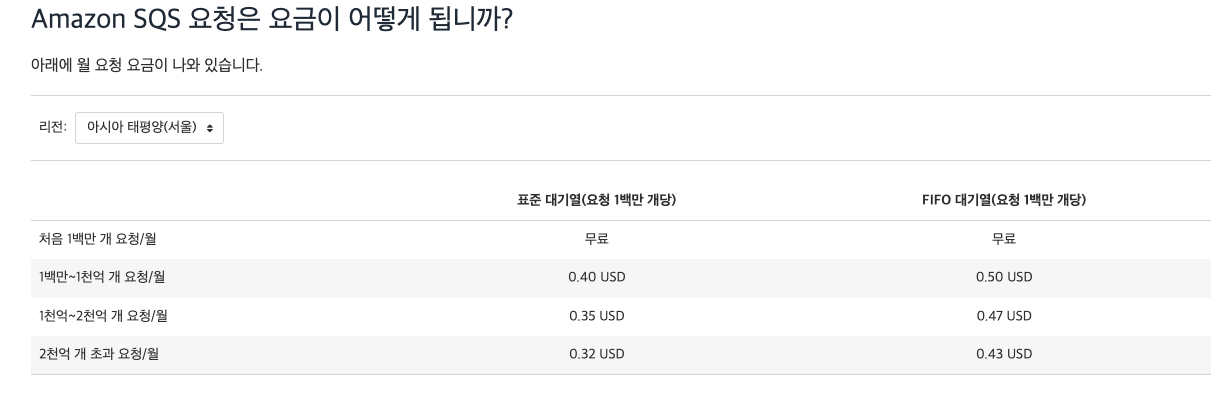
4. Labmda
서버리스 서비스이며, 파이썬, 노드, 자바 등등 다양한 런타임 환경을 제공한다. EC2와 다른 점은 사용한 시간만큼만 가격을 지불하면 된다는 점이다. 따라서 일시적으로 잠깐 동안 실행되는 CronJob에 어울리는 서비스다. 나는 파이썬으로 코드를 작성할 예정이다.
Lambda 비용은 아래와 같다. 실행한 시간만 지불하면, 되고 매우 저렴하다.
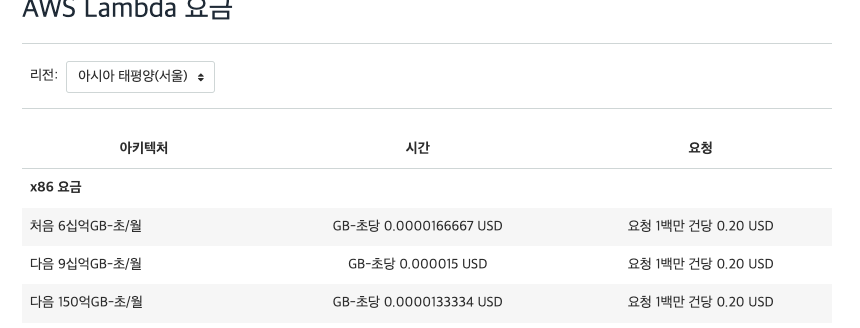
5. S3, S3 Glacier
S3에 로그가 저장되고, LifeCycle을 이용해서 일정 기간이 지난 데이터들을 아카이브 저장소인 Glacier로 이동시킴으로써 비용을 더욱 절감할 수 있다.
S3의 비용은 위에서 봤고, Glacier의 가격은 아래와 같다. S3에 비해서 약 70% 저렴하다.
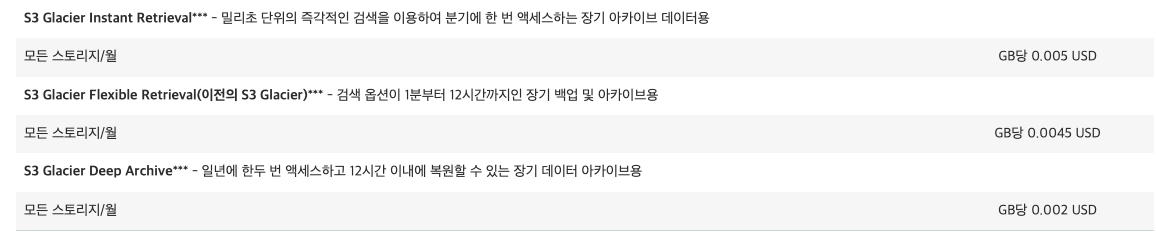
아키텍처에 대한 설계와 비용을 알아봤으니 이제 직접 만들어보겠다. 하나씩 따라올 수 있도록 만들 예정이고, 편의 실습을 위해 권한은 최소 설정은 지키지 않을 예정이다. 권한 최소 설정의 경우 하나씩 찾아보며 적용하기를 바란다.
2. 아키텍처 구현
아키텍처는 위와 같고, 가장 먼저 로그를 저장할 S3를 만들어야 한다.
2-1. S3, LifeCycle 구현
S3로 들어와서 만들기를 누른다. 이름만 원하는 이름으로 설정한 후에 다른 설정을 건드리지 않고, 만들기를 누른다.
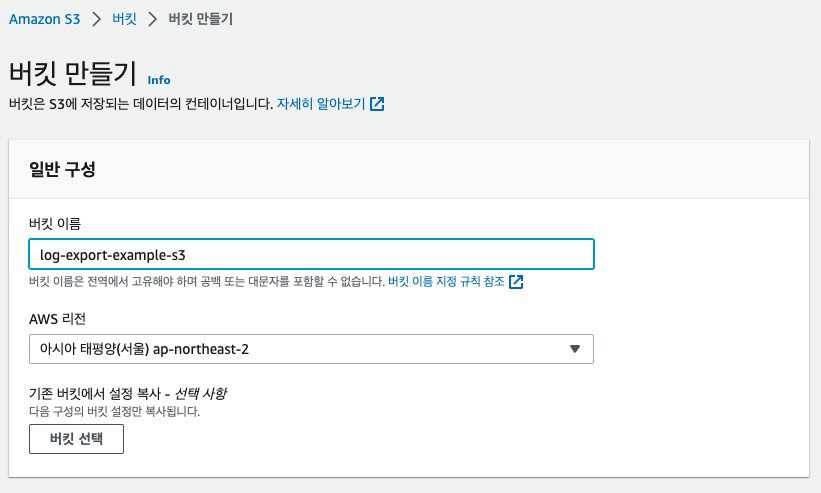
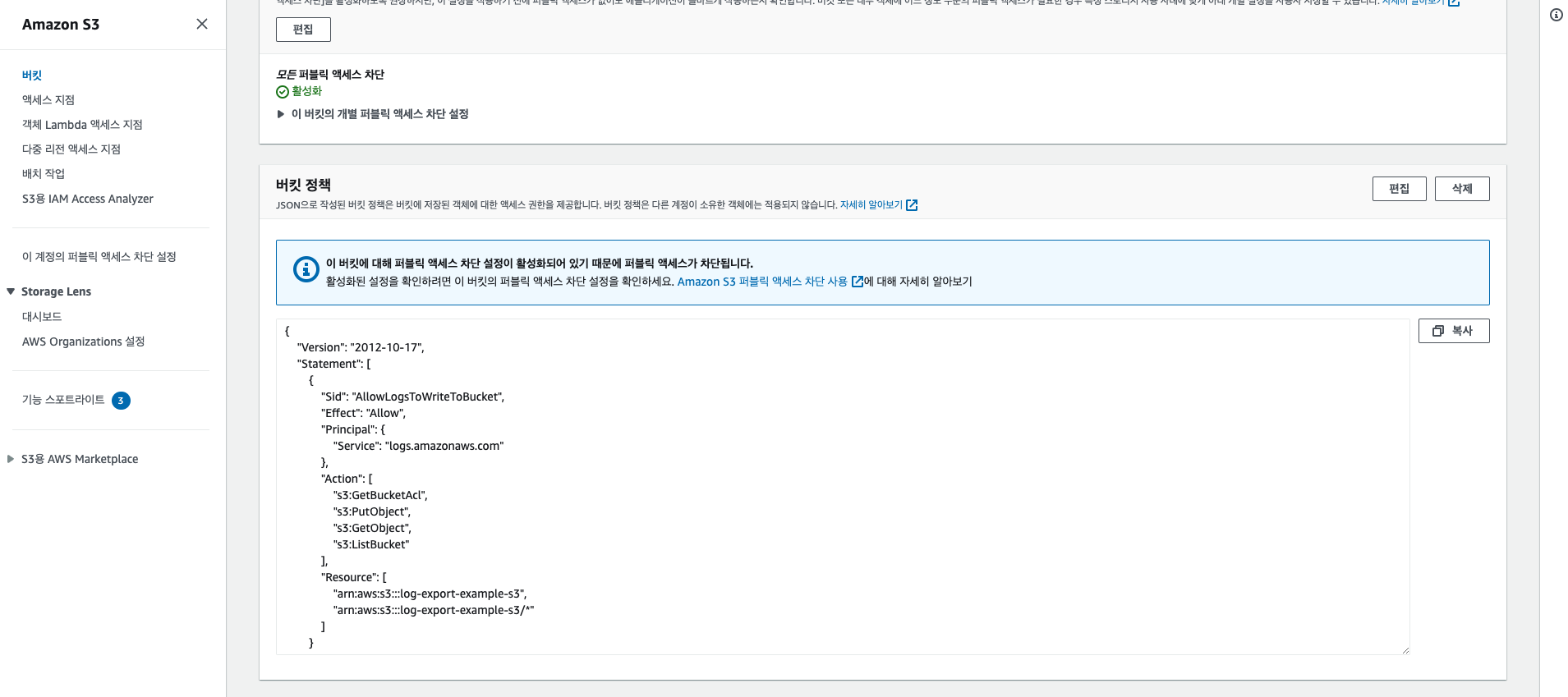
이제 CloudWatch에서 로그들을 저장할 수 있도록 권한 설정을 해줘야 한다. 권한 탭으로 이동한 후에 버킷 정책에 입력해 준다.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowLogsToWriteToBucket", "Effect": "Allow", "Principal": { "Service": "logs.amazonaws.com" }, "Action": [ "s3:GetBucketAcl", "s3:PutObject", "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::log-export-example-s3", "arn:aws:s3:::log-export-example-s3/*" ] } ] }
적용했다면 아래와 같이 입력이 된다.
이제 LifeCycle을 만들어야 한다. 관리탭으로 이동해서 수명 주기 규칙 생성을 눌러준다.
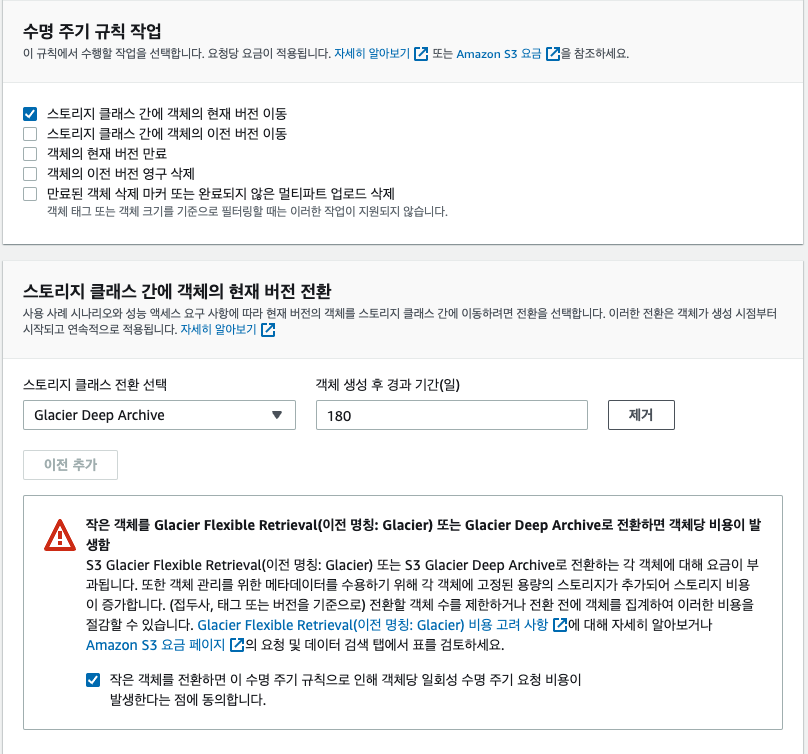
이름을 설정해 주고, 이 S3 버킷은 Log만 관리할 예정이므로 모든 객체에 적용을 눌러준다. 혹여나로 그들만 다 저장해야 할 성격이 다르다면, 접두사를 설정해서 설정할 수 있다. 나는 log_export_example_cloudwatch_log_stream의 로그 스트림을 저장할 예정이므로 그대로 따라 할 예정이라면, 이것을 접두사로 설정해 줘도 된다.
데이터의 유형에 따라 알맞은 Glacier유형을 선택해 주면 된다. 나는 Deep 유형을 선택했고, 해당 유형은 데이터를 요청했을 때 24~48시간 안에 받을 수 있는 유형이다. S3에 저장된 지 180 후에 Glacier Deep으로 이동하게 된다. 이제 생성을 해준다.
이제 S3에 대한 작업 설정은 모두 끝이 났다. 다음은 SQS를 설정해 보자.
2-2. SQS 구현
SQS서비스로 이동한 후 대기열 생성을 해준다. 이름은 log_export_example_sqs로 해준다. 유형은 표준으로 설정해 준다. FIFO는 선입 선출 개념으로 먼저 들어온 것을 처리하게 되는데, 우리로서는 필요 있는 설정은 아니다. 다른 설정들은 건드리지 않고 생성해준다. 만약 DeadLetter서비스를 이용하려면, 배달 못한 편지 대기열 설정을 해주면 된다.

2-3. SNS 구현
SNS 서비스로 이동한 후에 주제 생성하기를 눌러준 후 표준 유형을 선택한다. 이름은 log_export_example_sns로 해주었다. 다른 설정은 건드리지 않고, 만들어준다. 그럼 아래와 같이 생성된다.
이전에 SQS를 만들었으니 밑에 구독탭으로 이동하여, 이전에 만든 SQS를 구독자로 설정해준다.
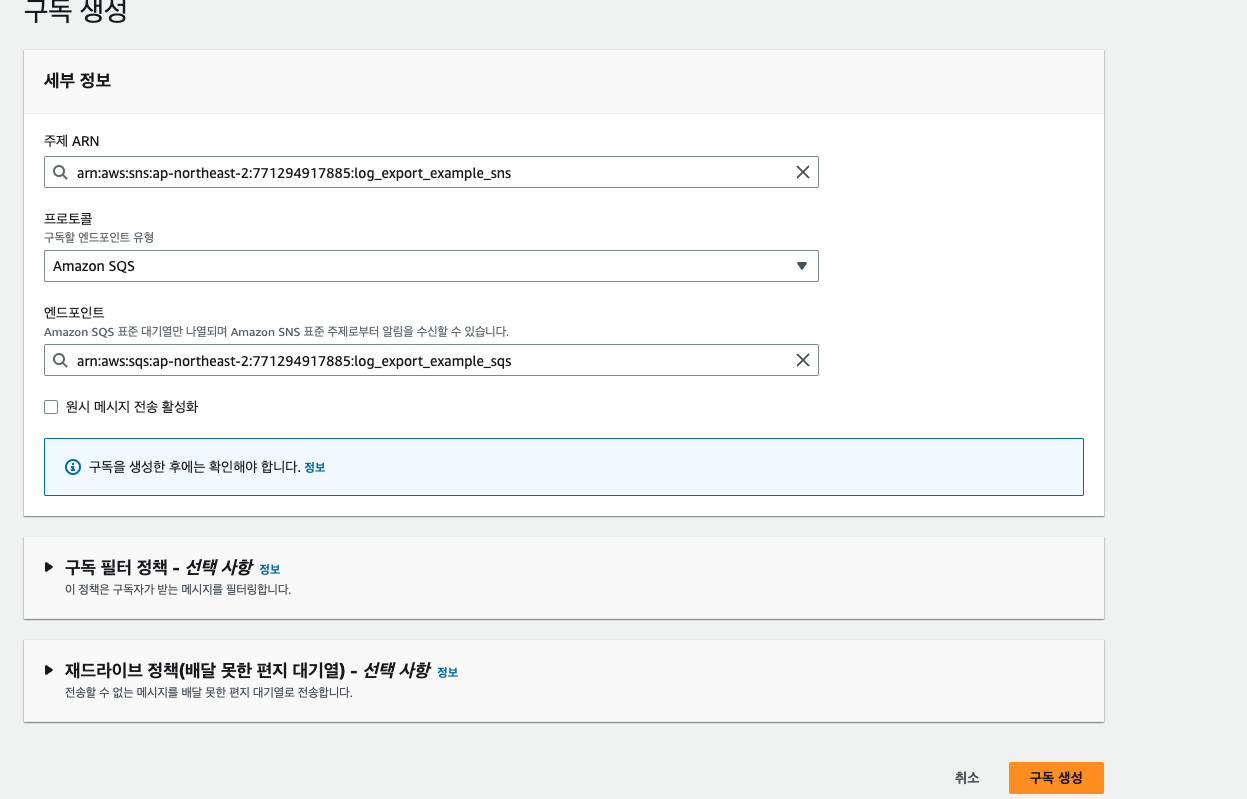
SNS에 대한 설정까지 모두 끝났다. 이제 Lambda를 구성해 보자.
2-4. Lambda
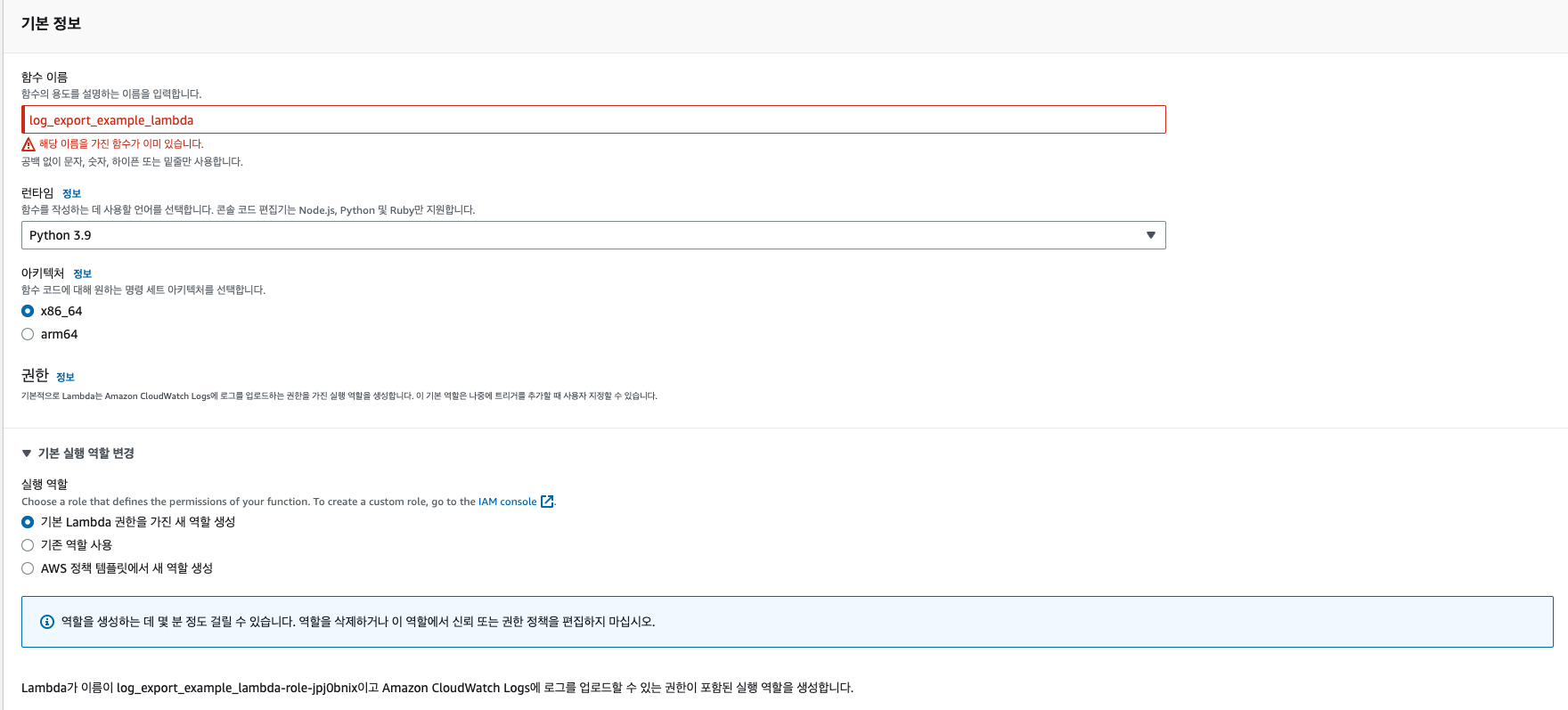
Lambda의 서비스로 이동한 후에 함수 생성을 한다. 이름을 log_export_example_lambda설정하고, 아래와 같이 설정해 준다. 실행역할은 기본으로 해주고, 이후에 수정할 예정이다. 생성되는데 조금 시간이 걸릴 수 있다.
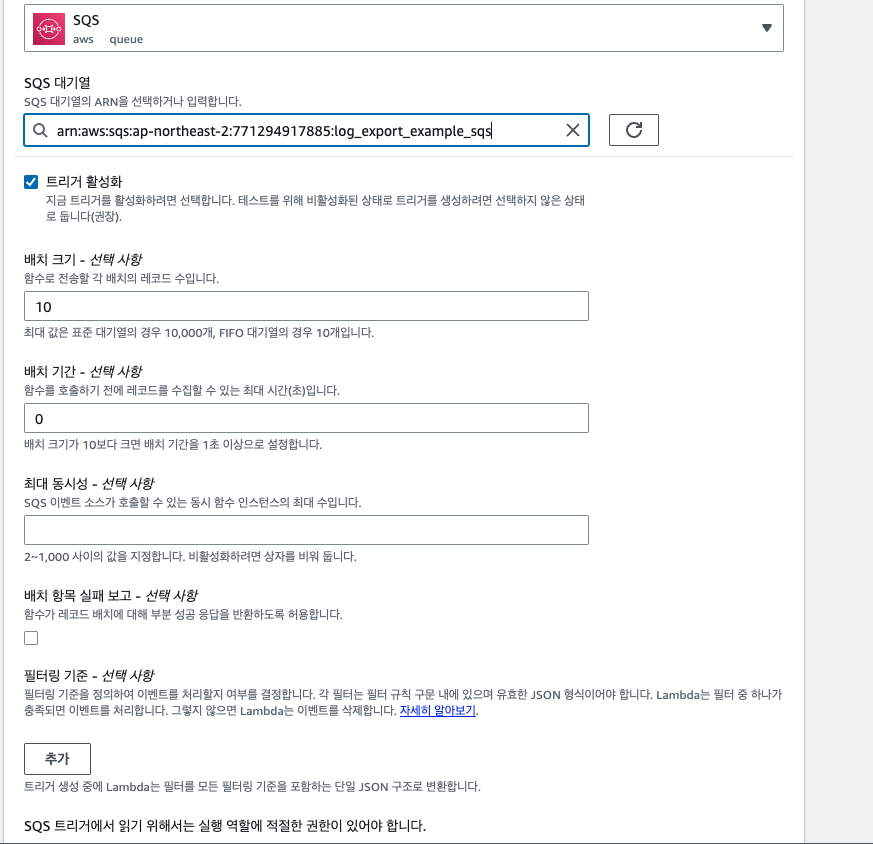
람다가 생성이 완료 됐다면, 트리거 설정먼저 해주자. 트리거를 클릭하고, SQS로 트리거를 설정한 후에 완료해 준다.
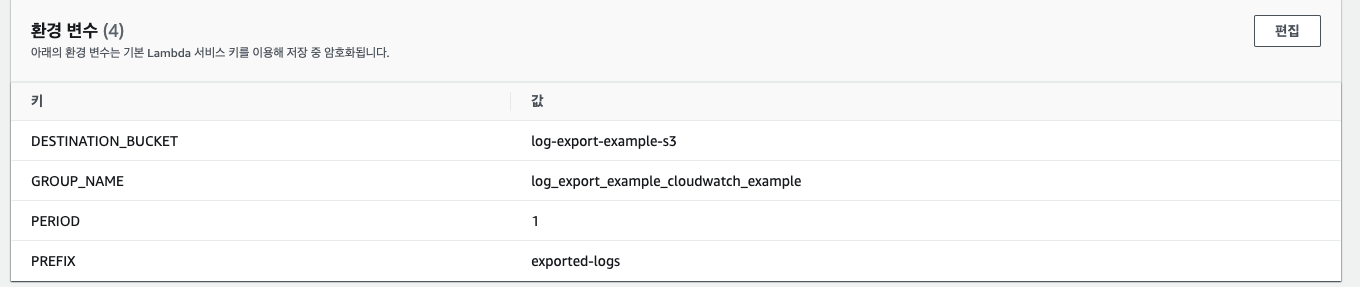
다음은 Labmda의 환경 변수 설정이다. 환경 변수 탭으로 이동한 후에 아래와 같이 구성해 준다. 이때 CloudWatch 로그 그룹은 자신이 사용하는 것을 넣어주면 된다. PERIOD는 얼마만큼의 시간의 로그들을 Export 할지 결정하는 변수이다. 내 설정은 하루치의 로그를 Export 한다.
이제 코드를 아래와 같이 입력해 준다.
import boto3 import os import datetime GROUP_NAME = os.environ['GROUP_NAME'] DESTINATION_BUCKET = os.environ['DESTINATION_BUCKET'] PREFIX = os.environ['PREFIX'] PERIOD = os.environ['PERIOD'] PERIOD = int(PERIOD) currentTime = datetime.datetime.now() startDate = currentTime - datetime.timedelta(PERIOD) endDate = currentTime - datetime.timedelta(PERIOD - 1) fromDate = int(startDate.timestamp() * 1000) toDate = int(endDate.timestamp() * 1000) BUCKET_PREFIX = os.path.join(PREFIX, startDate.strftime('%Y{0}%m{0}%d').format(os.path.sep)) def lambda_handler(event, context): print(currentTime, startDate, endDate, PERIOD, fromDate, toDate) client = boto3.client("logs") client.create_export_task( logGroupName= GROUP_NAME, fromTime = fromDate, to=toDate, destination=DESTINATION_BUCKET, destinationPrefix=BUCKET_PREFIX )
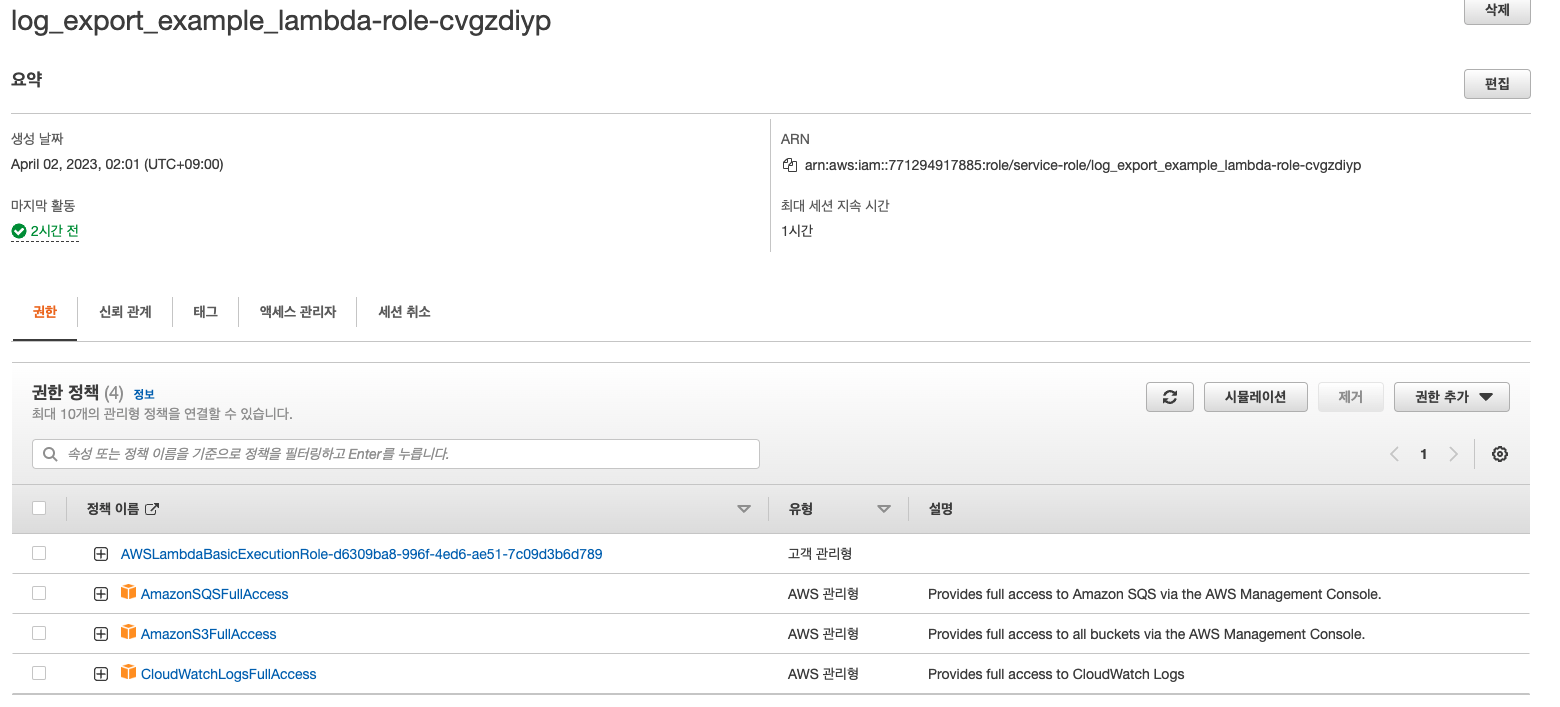
이제 Lambda의 역할만 수정해 주면, 끝이 난다. IAM으로 이동한 후에 Lambda에게 부여된 IAM역할을 찾고 추가적인 정책을 연결해 준다.
가장 위에 있는 정책은 Lambda가 생성될 때 기본 정책이고, 나머지 3개의 정책을 연결해 준다. 위에서 언급했듯이 최소 정책을 사용하지는 않을 예정이다.
이제 EventBridge의 CronJob을 만들기 전에, 테스트를 진행해 보자. 코드의 Delpoy를 누른 후에 Test를 생성하고, Lambda가 정상 동작하는지 확인해 보자.
아래와 같이 테스트 탭에서 테스트를 생성하고 테스트를 돌려보자.
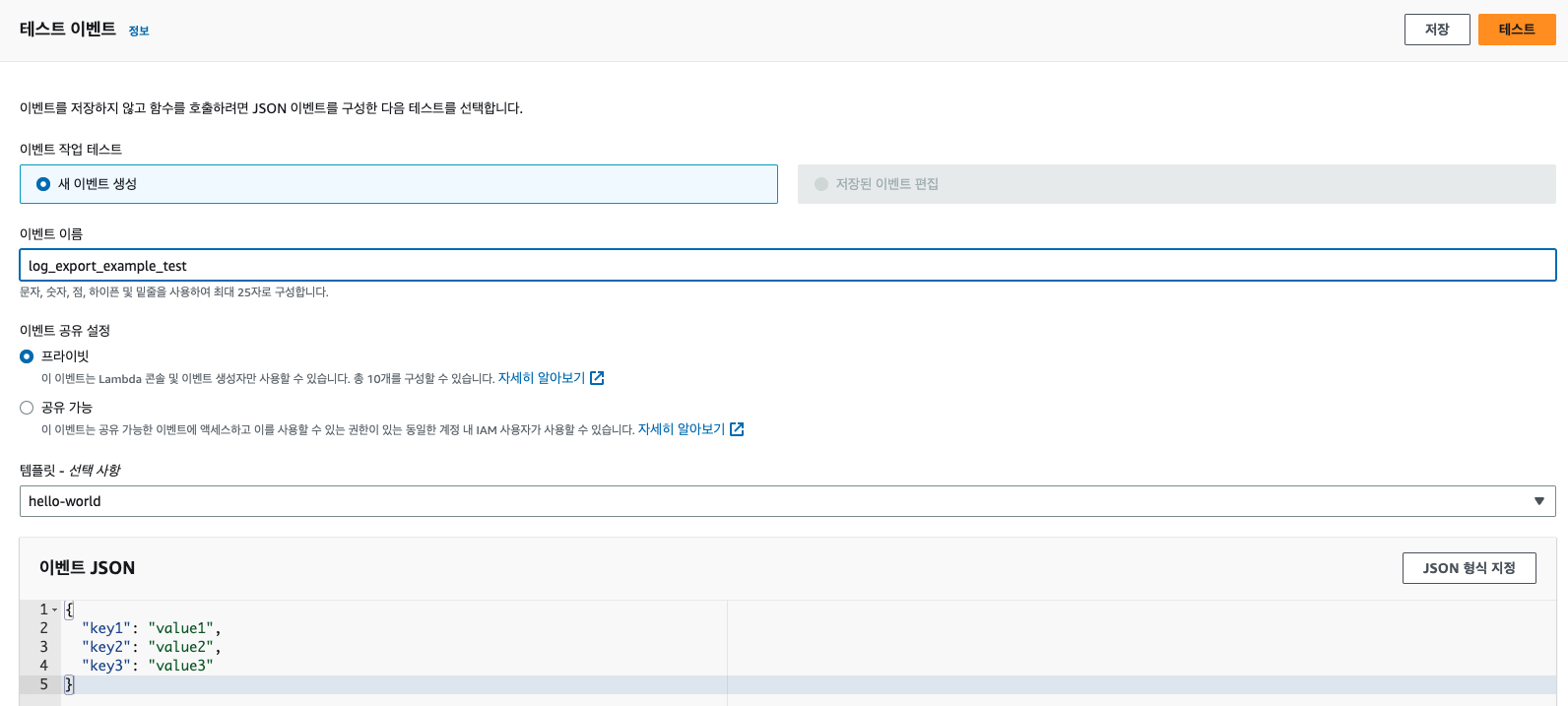
정상적으로 실행된다면, 아래와 같이 뜰 것이고, 실패한다면 로그를 살펴보고 수정해 주면 된다. 이제 S3에 로그가 들어왔는지 확인해 보자.

내가 설정한 prefix/year/month/day/UUID/로그 그룹이름 아래에 객체가 저장된 것을 볼 수 있다.
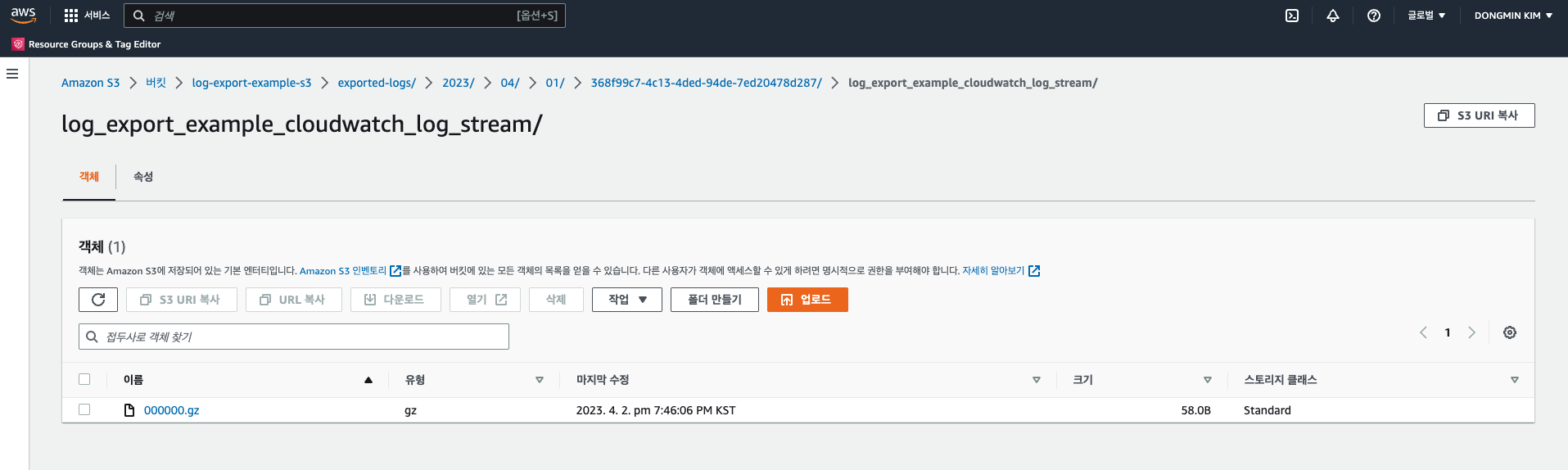
정상적으로 들어온 것을 봤다면, 이제 EventBridge만 설정해 주면 끝이다.
2-5. EventBridge
EventBridge 서비스로 이동한 후에 일정 유형을 선택하여 생성한다.
이름은 log_export_example_eventbridge로 설정할 예정이고 아래에 일정을 생성해 주자. CronJob 정규식은 한 번 찾아보며, 자신에게 맞는 것으로 설정하기를 바란다. 나는 Lambda에서의 로그 Export 기간이 1일이기에 EventBridge의 주기도 1일로 설정해야 한다.
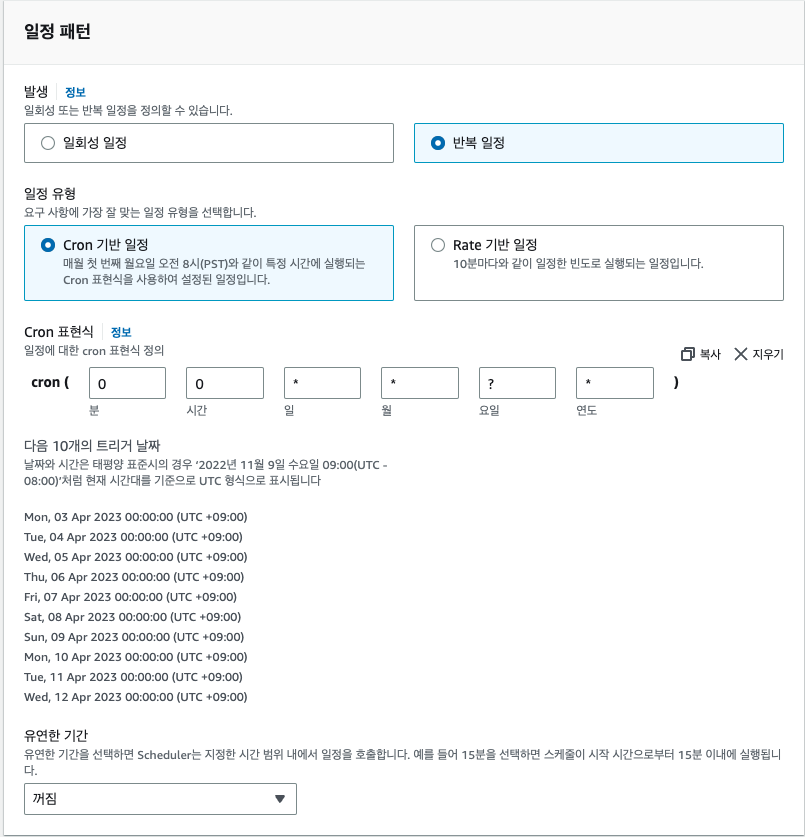
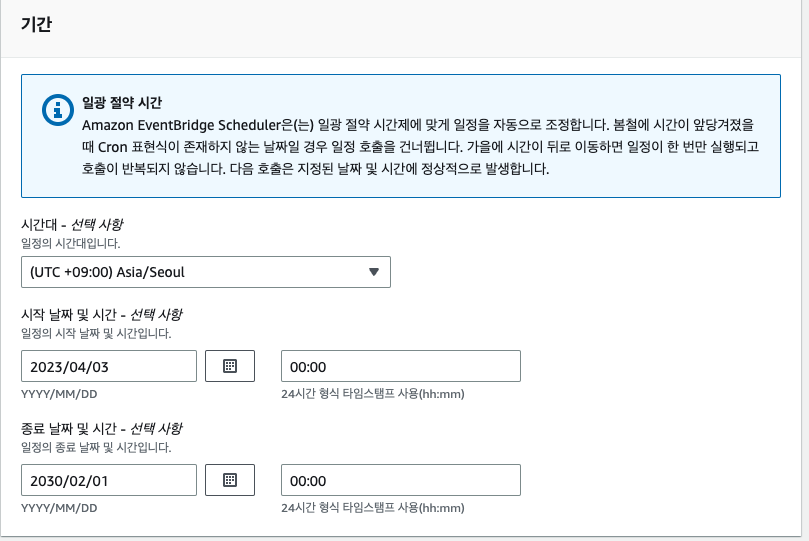
언제부터 시작하고, 끝내는지 일정을 설정해 준다. 오늘의 로그는 내일 수동으로 Export 하고 내일 00시부터 발생하도록 하면 빠지는 로그 없이 Export 되게 할 수 있다.
SNS에 토픽에 메시지를 게시해야 했기에 SNS Publish 유형을 선택하고, 이전에 만든 SNS 토픽을 선택해 준다.
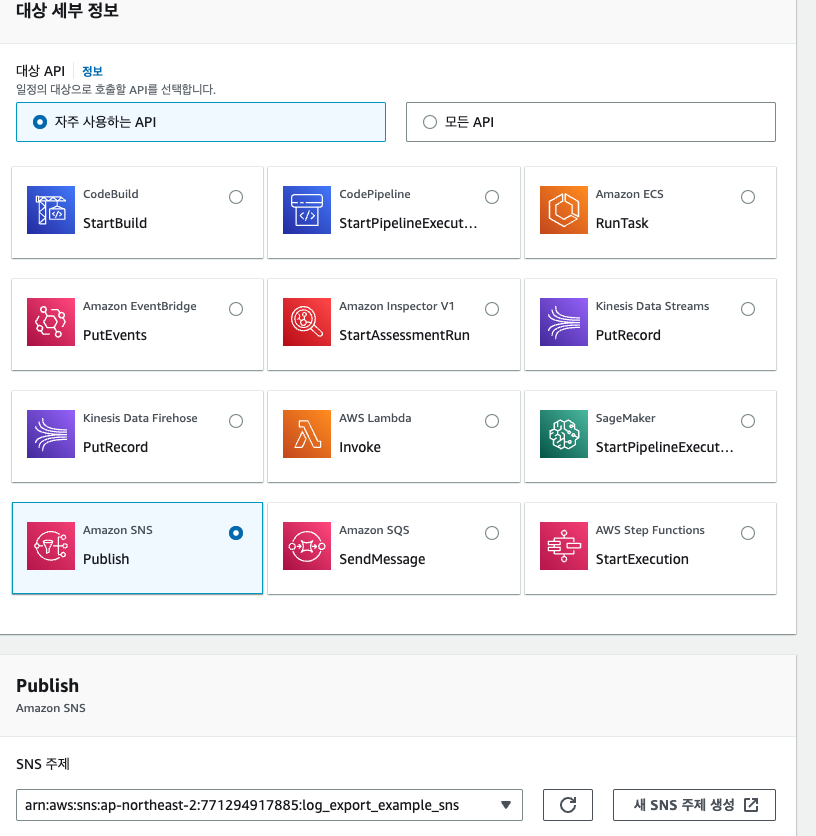
그 후의 설정은 건드리지 않고 생성을 완료해 준다.
이로써 매일 00시마다 하루치의 로그가 자동적으로 CloudWatch에서 S3로 이동시켜 줄 것이다.
3. 주의점
매우 간략하게 아키텍처를 만들면서, 몇 가지 주의점이 생각났다.
3-1. 권한 설정
현재 Lambda의 권한은 S3, CloudWatchLog, SQS의 FullAccess 권한으로 최소 권한을 설정하지 않았다. 지금으로서는 문제 되지 않지만, 이 역할을 돌려서 다른 서비스에서도 사용할 경우 의도하지 않은 동작이 발생할 수 있다.
또한 S3의 버킷 정책도 매우 느슨한 버킷 정책이다. Cloudwatch의 해당 로그 그룹만 PUT 할 수 있도록 권한 설정을 더 최소한으로 유지한다면, 더 좋은 아키텍처가 될 수 있을 것이다.
3-2. 로그 그룹 보존 기간 설정
진행하며 눈치 채신 분들도 있지겠지만, 로그를 자동으로 Export 하는 것에 한 눈 팔려 정작 CloudWatch의 로그 그룹에 보존 기간을 설정해주지 않았다. 이것은 로그 그룹의 작업 -> 보존 설정 편집을 해주면 된다. Default 설정이 영구 보존이기에 이것을 바꿔주지 않는다면, CloudWatch, S3 두 곳에서 과금이 되기에 원래 목적인 비용 절감을 할 수 없게 된다. CloudWatch 대시보드를 이용해서 모니터링을 진행한다면, 원하는 모니터링 기간에 맞게 보존 기간을 설정하면 될 것이다. 영구 보존은 비용적 측면에서 올바르지 못하다.
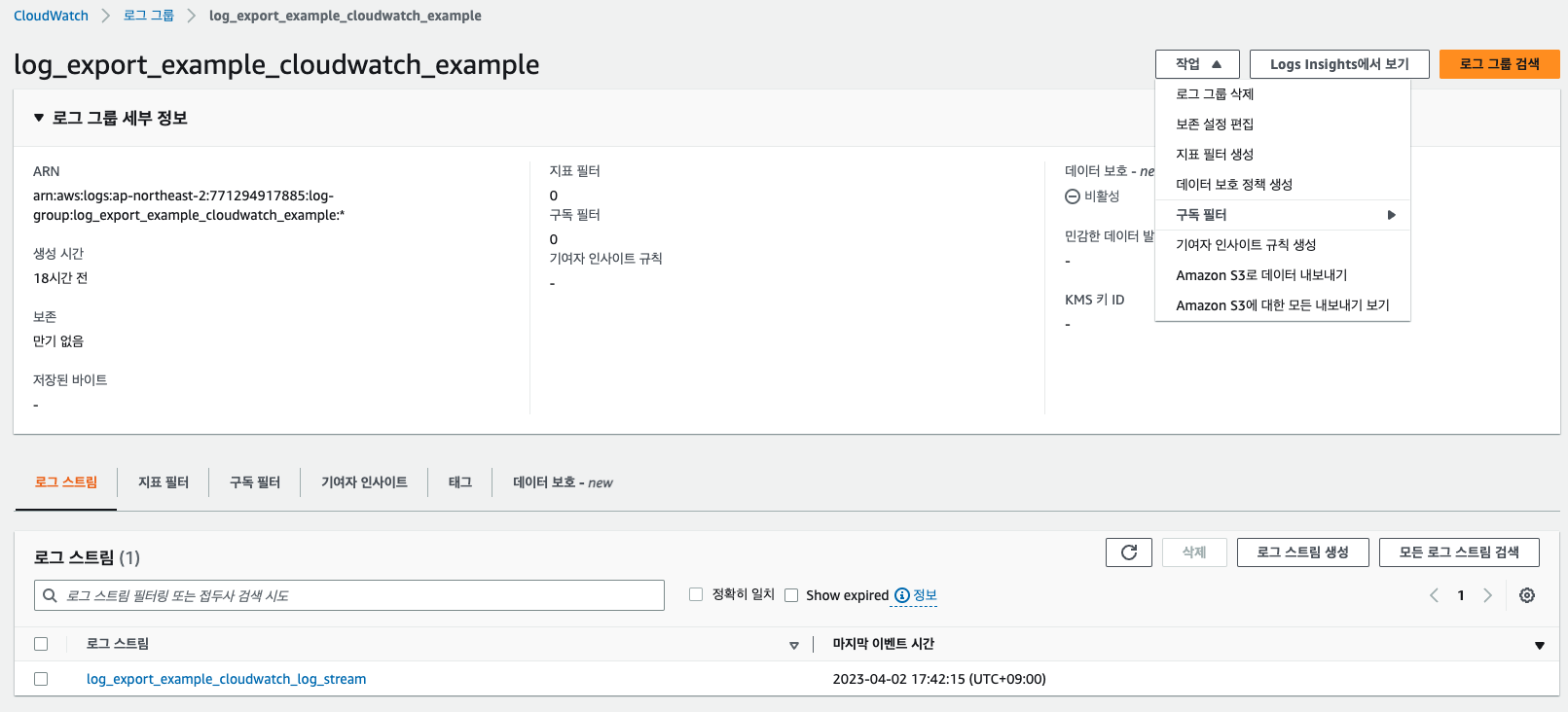
4. 결론
서비스를 운영하며, 비용이 발생하는 것에 신경이 쓰일 수밖에 없다. 하지만 서버 개발자가 일을 하면서 비용 절감에 대해서 깊은 고민을 할 수 있는 시간이 많지 않다. 따라서 눈에 보이고, 가장 쉬운 해결책 먼저 찾아나가게 된 것 같다. 그것이 로그들에 대한 비용들이었다. 나의 아키텍처가 완벽하지는 않지만, 많은 분들에게 도움이 됐으면 한다.
'Aws' 카테고리의 다른 글
| S3를 CloudFront로 제공하기 (0) | 2023.05.08 |
|---|---|
| EKS Fargate 유형 애플리케이션 로그 수집 Part 1 (0) | 2023.04.05 |
| AWS Solution Architect Associate(SAA-C03) 취득 후기 (16) | 2023.03.27 |
| AWS EC2 초기 설정하기 (0) | 2021.12.29 |
| AWS EC2 탄력적 IP (0) | 2021.12.27 |
댓글을 사용할 수 없습니다.