저렴하게 실시간 분석 아키텍처 만들기 with aws, terraform
서비스를 운영하며 수집되는 데이터는 방대하고 이러한 데이터들 속에서 어떻게 인사이트를 얻어서 서비스를 발전시킬 수 있을까?? 항상 진행하고 싶은 업무 중의 하나이다. 인사이트를 얻기 위해선 데이터를 분석할 수 있는 아키텍처가 필요하다.
이러한 아키텍처에서 요구되는 기능은 보통 아래와 같다.
1. 데이터 수집
2. 데이터 처리 및 변환
3. 변환 데이터 저장
4. 데이터 분석
여기서 해당 기능들을 사용할 수 있는 다양한 서비스들을 사용할 수 있다. 하지만 나는 최대한 저렴하게 이용할 수 있는 아키텍처를 구성해보자.
아키텍처
가격은 저렴하고, 확장성 있게 만들어보려고 한다. 그래서 나는 아래와 같이 선택했다.
1. 데이터 수집 -> Kinesis Data Firehose PUT API
2. 데이터 처리 및 변환 -> Kinesis DataFirehose & Lambda
3. 변환 데이터 저장 -> S3
4. 데이터 분석 -> Athena
애플리케이션에서 Kinesis DataFirehose의 PUT API를 이용해서 KinesisData Firehose로 보내고 적정한 크기의 버퍼를 설정하고 Lambda 데이터를 변환하여 S3로 보낸다.
S3에서 형식에 맞게 저장된 데이터를 Athena를 통해서 쿼리를 보낼 수 있다. 이것을 Amazon QuickSight와 연동해서 시각화를 할 수 있다. 아니면 Grafana를 따로 구현해서 할 수 도 있다.
전체적인 아키텍처는 아래와 같다.

요즘 rust를 공부하고 있어서 rust 코드로 간단하게 아래와 같이 구현해 봤다.
use std::env; use aws_config::default_provider::region::DefaultRegionChain; use aws_config::default_provider::credentials::DefaultCredentialsChain; use aws_sdk_firehose::{Client, Error}; use aws_sdk_firehose::model::Record; use aws_sdk_firehose::types::Blob; use serde::{Deserialize, Serialize}; use std::process; #[derive(Serialize, Deserialize, Debug)] struct Data { name: String, age: i32, } #[tokio::main] async fn main() -> Result<(), Error> { let profile = env::args().skip(1).next().expect("profile to use is required"); let region = DefaultRegionChain::builder().profile_name(&profile).build().region().await; let creds = DefaultCredentialsChain::builder() .profile_name(&profile) .region(region.clone()) .build() .await; let config = aws_config::from_env().credentials_provider(creds).region(region).load().await; let client = Client::new(&config); // Define the data to send let data = Data { name: "test".to_string(), age: 10, }; // Serialize the data to JSON let data_json = serde_json::to_string(&data).expect("Serialization failed"); // Define the delivery stream name let firehose = "data-analytics"; // Create a PutRecordInput request let record = Record::builder() .data(Blob::new(data_json.into_bytes())) .build(); let request = client .put_record() .delivery_stream_name(firehose) .record(record); // Send the record to Firehose match request.send().await { Ok(_) => println!("Record submitted successfully!"), Err(e) => { eprintln!("Failed to submit record: {}", e); process::exit(1); } } Ok(()) }
aws-config = "0.13.0" aws-sdk-firehose = "0.13.0" tokio = { version = "1", features = ["full"] } serde = { version = "1.0", features = ["derive"] } serde_json = "1.0"
디펜던시는 아래와 같다.
그럼 이제 Terraform으로 만들어야 할 것은 아래와 같다.
1. S3
2. Kinesis Data Firehose
3. Lambda
4. Athena
이다. terraform 코드는 여기 Github에서 볼 수 있다.
Lambda에서 쓰이는 코드는 아래와 같다.
use lambda_runtime::{service_fn, Error, LambdaEvent}; use serde::{Deserialize, Serialize}; use serde_json::{json, Value}; use base64::decode; #[derive(Deserialize)] struct Record { recordId: String, data: String, } #[derive(Deserialize, Debug)] // Debug 트레이트 추가 struct Data { age: u32, } #[derive(Serialize)] struct OutputRecord { recordId: String, result: String, data: String, metadata: Metadata, } #[derive(Serialize)] struct Metadata { partitionKeys: PartitionKeys, // 필드 이름 수정 } #[derive(Serialize)] struct PartitionKeys { age: String, } #[tokio::main] async fn main() -> Result<(), Error> { lambda_runtime::run(service_fn(handler)).await?; Ok(()) } async fn handler(event: LambdaEvent<Value>) -> Result<Value, Error> { let (event, _context) = event.into_parts(); let records = event["records"].as_array().unwrap(); let mut output = Vec::new(); for record in records { let record_id = record["recordId"].as_str().unwrap().to_string(); let data_base64 = record["data"].as_str().unwrap(); let decoded_data = decode(data_base64).unwrap(); let payload: Data = serde_json::from_slice(&decoded_data).unwrap(); let partition_keys = PartitionKeys { age: payload.age.to_string(), }; let output_record = OutputRecord { recordId: record_id, result: "Ok".to_string(), data: data_base64.to_string(), metadata: Metadata { partitionKeys: partition_keys }, // 올바르게 수정 }; println!("{:?}", payload); // Debug이므로 이제 오류 없음 output.push(output_record); } Ok(json!({ "records": output })) }
Dockerfile은 이거다.
FROM rust:1.70 as builder WORKDIR /usr/src/app COPY Cargo.toml Cargo.lock ./ RUN mkdir src && echo "fn main() {}" > src/main.rs && cargo fetch COPY src ./src RUN cargo build --release # 실행 스테이지 FROM public.ecr.aws/lambda/provided:al2023-arm64 COPY --from=builder /usr/src/app/target/release/docker ${LAMBDA_RUNTIME_DIR}/bootstrap CMD ["bootstrap"]
athena에서 테이블을 생성할 때 쓰이는 쿼리는 아래와 같다.
CREATE EXTERNAL TABLE IF NOT EXISTS `data_analytics`.`person` (`name` string) PARTITIONED BY ( `year` int, `month` int, `day` int, `age` int ) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' WITH SERDEPROPERTIES ( 'ignore.malformed.json' = 'FALSE', 'dots.in.keys' = 'FALSE', 'case.insensitive' = 'TRUE', 'mapping' = 'TRUE' ) STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://data-analytics-dkim/' TBLPROPERTIES ('classification' = 'json');
이제 테스트해보자.
아테나는 테이블을 만들고 파티션은 로드해줘야 정상 동작한다. 쿼리는 아래와 같다.
MSCK REPAIR TABLE `person`;
이제 kinesis firehose로 데이터를 삽입하는 코드를 실행시키자. 나는 rust로 작성했지만, 다른 코드로 해도 무방하다.
kinesis -> lambda -> s3로 동작하여 아래와 같이 데이터가 쌓이게 된다.
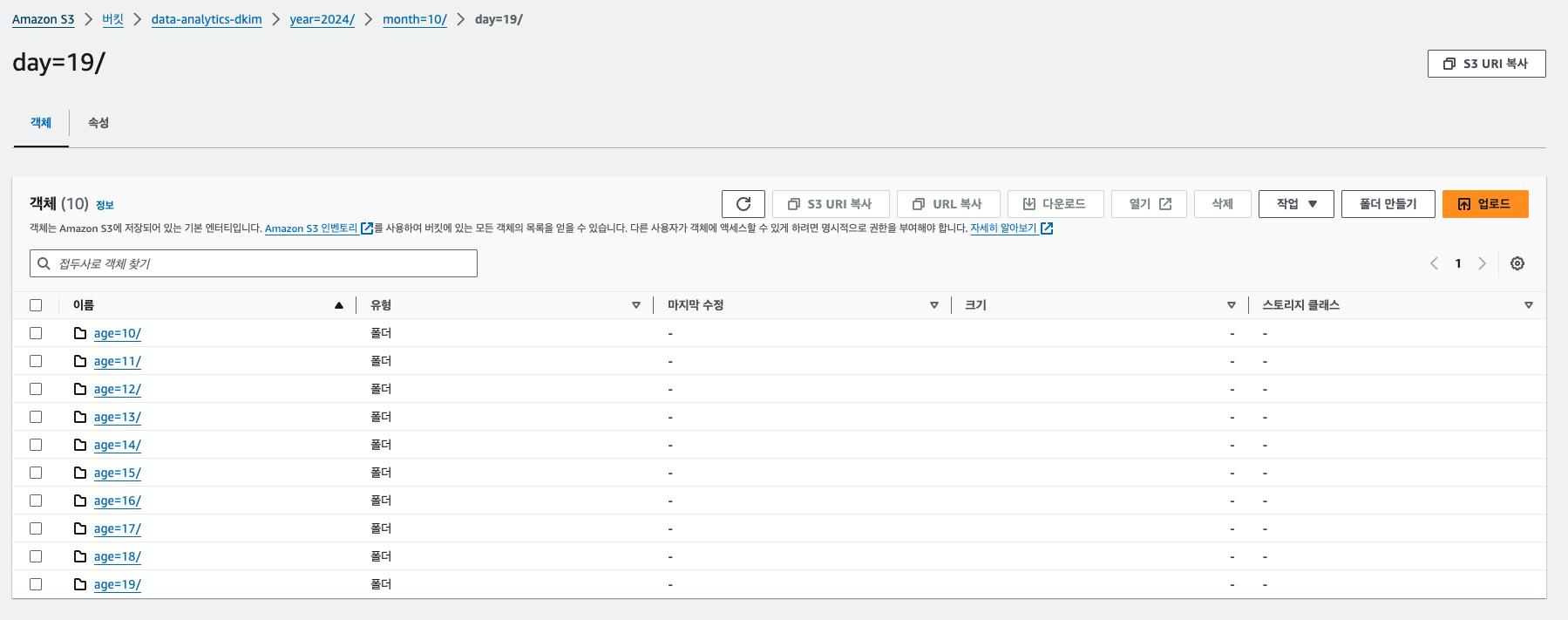
이제 아테나에 쿼리를 실행할 수 있고, 아래와 같이 조회된다.
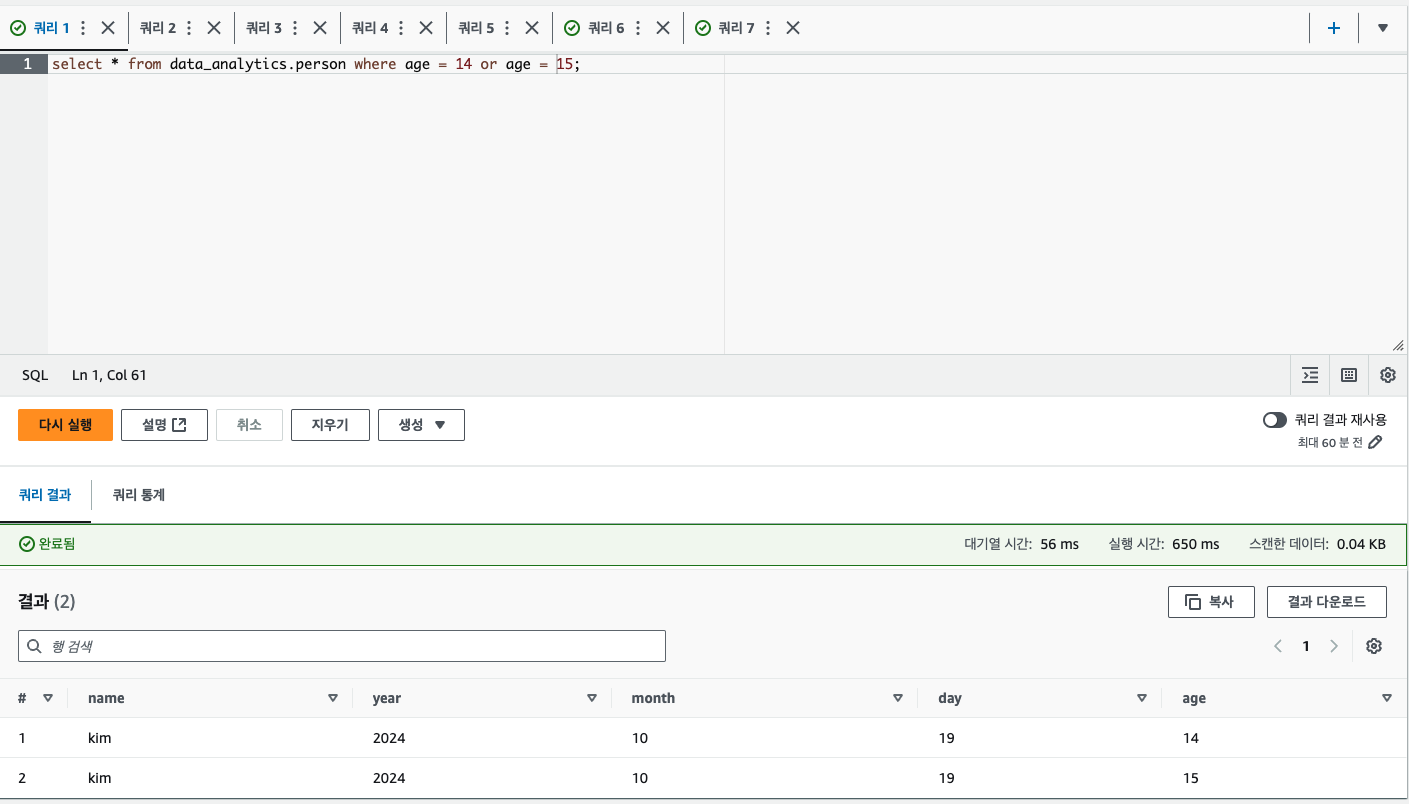
다른 데이터 분석 아키텍처도 존재하지만 내가 가장 저렴하다고 한 이유는 모두 사용한 만큼만 비용을 지불하기 때문이다.
현재는 Lambda 코드에서 별도의 데이터 변환하지 않았지만, 데이터를 가공할 수 있어 유연하게 변경 가능하다.
하지만 문제점도 있다.
1. 이전에 쌓지 못한 데이터는 Glue를 이용해서 S3에 적재해줘야 함.
2. API가 생기거나 분석할 데이터가 생길 때마다 firehose 혹은 lambda 코드를 변경해야 함
물론 가격과 편리함의 트레이드오프가 존재하는 거 같다.
시각화 도구는 오픈 소스를 사용해도 되고, Quicksight를 사용해도 된다.
'Aws' 카테고리의 다른 글
| AWS Private Subnet S3 Data Transfer 비용 (2) | 2024.11.05 |
|---|---|
| Aws Lambda 파일 시스템의 필요성 (0) | 2024.10.24 |
| AWS S3 LifeCycle with Terraform (0) | 2024.09.28 |
| AWS Security Specialty (SCS-C02) 취득 후기 (1) | 2024.01.23 |
| AWS CloudFront 정적 + 동적 컨텐츠 캐시 활용 - 1 (1) | 2023.11.30 |
댓글을 사용할 수 없습니다.